
Topic 2B Part 2 – Unsupervised Learning
There are three kinds of ML problems (or tasks) – this topic is split into three parts to explain each of them.
Supervised Learning is a method of training an algorithm where a data set consists of two parts: The data itself and a label. For example, a picture of a strawberry and a label which describes it as a strawberry.
The algorithm is rewarded when it predicts the correct label, and it can rearrange itself if it predicts the wrong label.
Similarly, the data can be associated with a real number, representing for example a geophysical parameter, rather than with a label. This is an example of regressions, where the task is to predict a continuous quantity.
This can be used to do two things:
- Classification: sorting data into classes
- Regression: parameter estimation
Featured Educators:
- Nicolo Taggio
No items found.
Optional Further Reading
Featured Images and Example Data

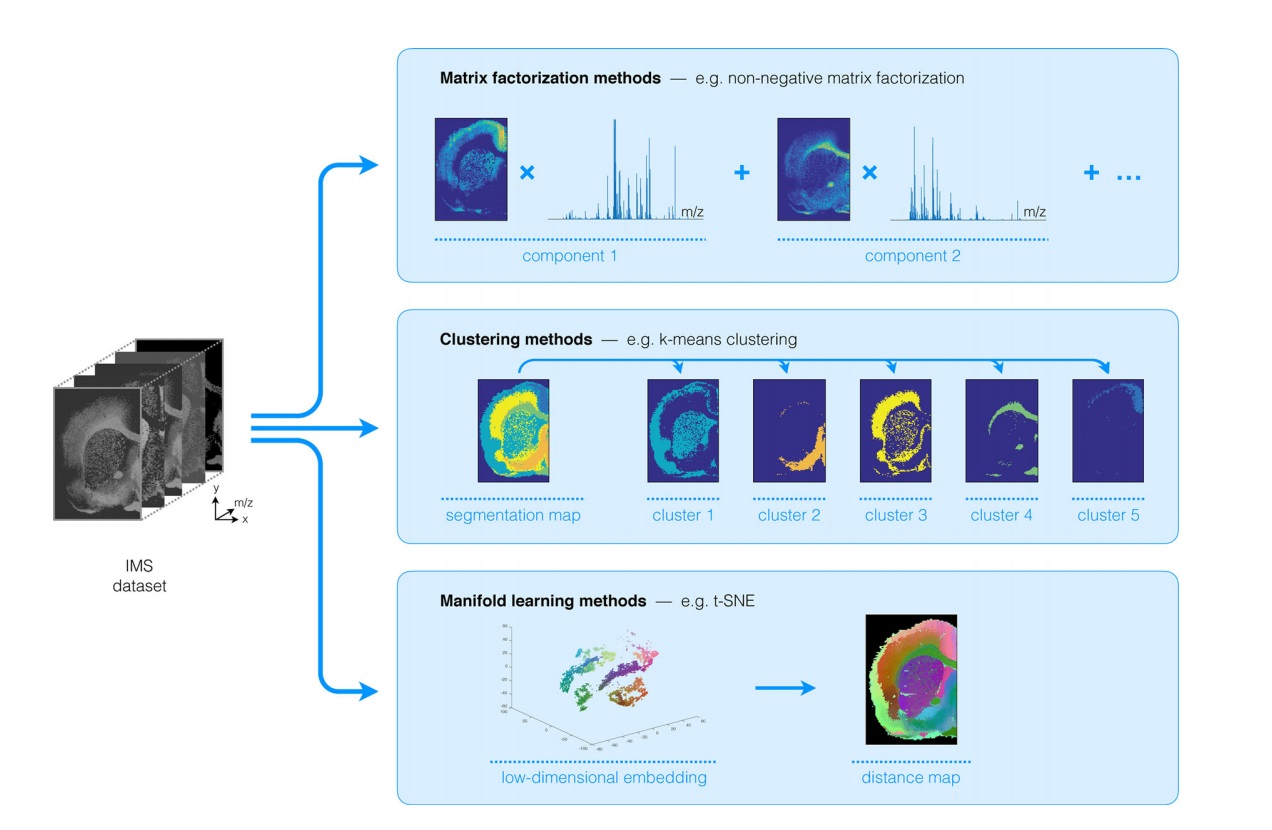
Unsupervised machine learning methods
This is an example of unsupervised learning methods used for Imaging Mass Spectrometry (IMS)
©
Nico Verbeeck, at al, 2019
Source LinkFeatured Video and Animations

Sentinel-3 scans Earth's colour
Animation of Sentinel-3 using it's Ocean and Land Colour Instrument (OLCI) instrument
©
ESA/ATG medialab
Source LinkDownload Resources
No items found.
Discussion
Sign up to our newsletter to get updates from Imperative MOOCs
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.
No items found.